Capire il Machine Learning (parte 3)
15 November 2016
15 November 2016
Il machine learning viene utilizzato anche per il riconoscimento delle immagini. La tipologia di rete neurale utilizzata per questa applicazione è chiamata rete neural a convoluzione ( convolutional neural networks), abbreviata CNN.
Innanzitutto consideriamo che ogni immagine può essere codificata come una matrice di valori
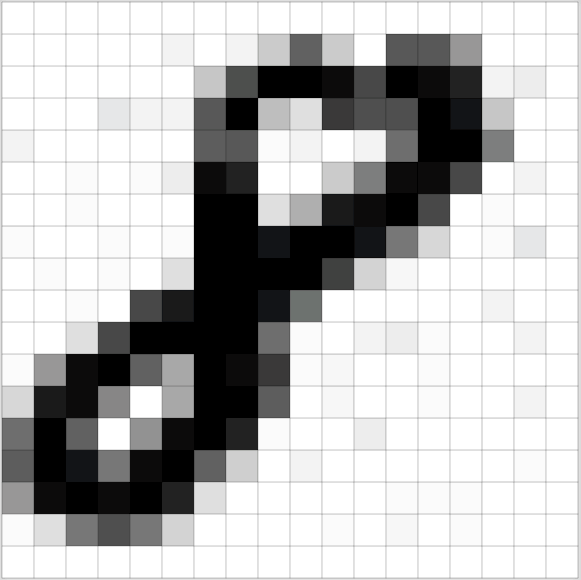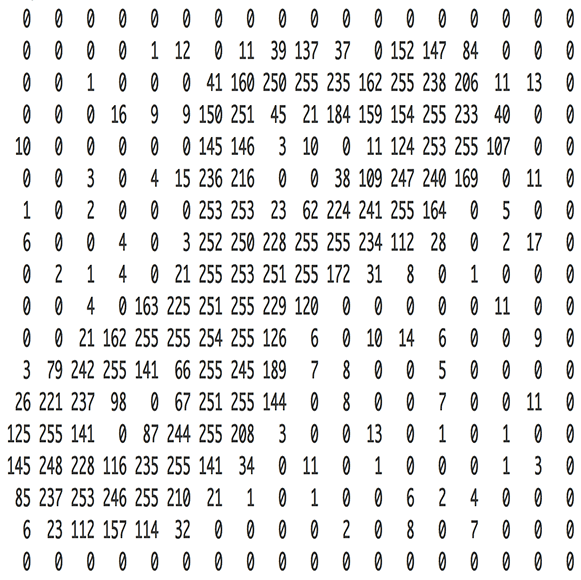
Vediamo ora quali sono le operazioni compiute da una CNN per riconoscere delle immagini.
Durante la fase di apprendimento, la rete neurale analizza moltissime immagini (categorizzate) utilizzando dei "filtri", ovvero delle funzioni che mescolate all'input originale permettono di evidenziare dei pattern nell'immagine. Questi pattern corrispondono alle caratteristiche proprie di un oggetto (quali possono essere ad esempio per un uccello il becco, le piume, le ali) e nel caso queste sono presenti, possiamo riconoscere l'immagine.
In questo esempio l'immagine di Wally é mescolata (l'operazione si chiama convoluzione) con un filtro "a cerchio" che risponde molto bene a caratteristiche come quella di possedere degli occhi.
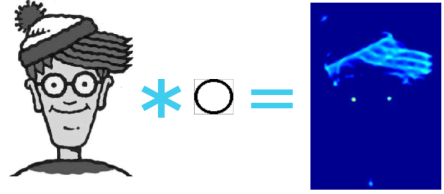
La convoluzione é un'operazione che ha la proprietà di essere indipendente dalla posizione. Non importa la posizione degli occhi, quando applichiamo la convoluzione su un'immagine con un filtro "a cerchio" notiamo che gli occhi sono presenti.
Ogni segnale contiene del "rumore", ovvero degli elementi che la allontanano dal comportamento ideale.
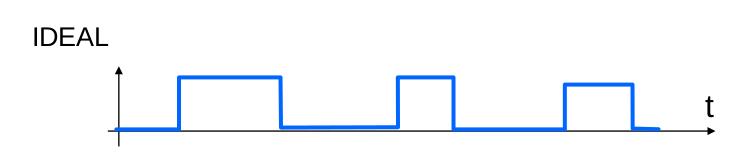

Attraverso il subsampling possiamo ridurre il rumore e rendere il nostro algoritmo meno suscettibile a queste piccole variazioni; benché l'immagine abbia una risoluzione minore, i pattern rimangono.

Alla fine dell'analisi tutte le caratteristiche estrapolate vengono considerate nell'insieme e in questo modo possiamo capire a quale categoria appartiene l'immagine.
Questo procedimento a livello algoritmo si esplicita con una connessione completa fra tutti i nodi della rete neurale che possono poi restituire l'output (probabilità che l'immagine appartenga ad una determinata categoria).
Durante il training é presente un'ultima fase (o strato), chiamato più propriamente loss layer. Questo strato provvede a dare un feedback alla rete neurale analizzando l'output in relazione ai dati di partenza (ovvero le immagini già categorizzate).